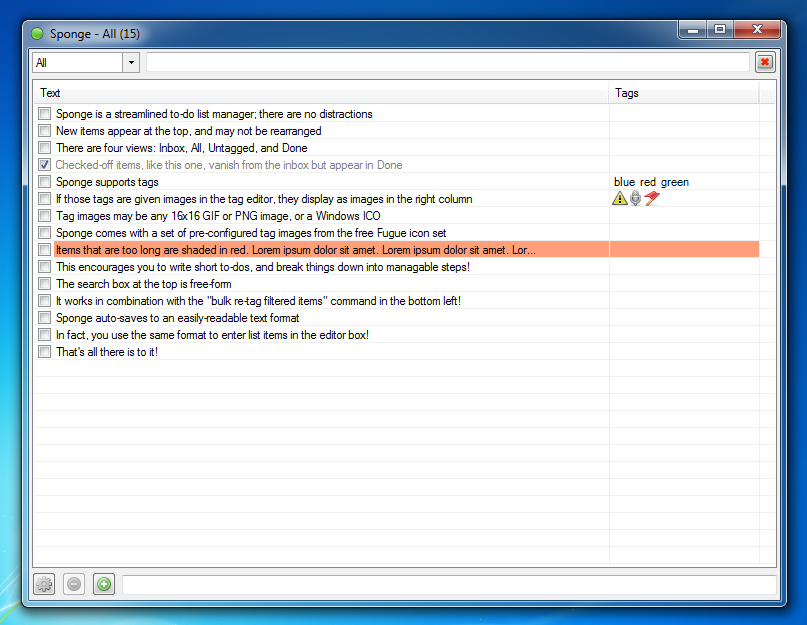
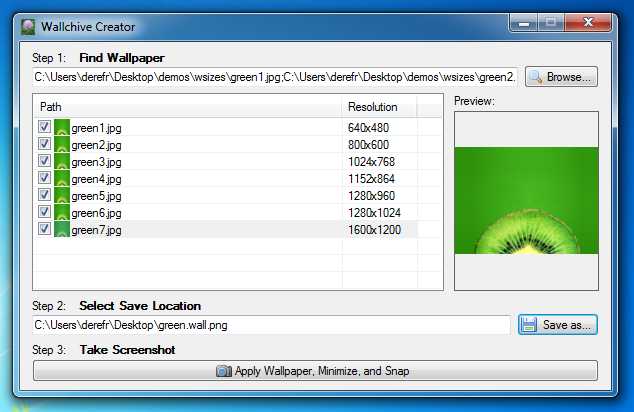
About Me
Hi, I'm Levi: a reliable, talented and industrious generalist software developer, working out of Vancouver, British Columbia. I believe in my work, and am always looking for ways to better my skills. I'm an excellent communicator, and enjoy an iterative development process, putting the client at the center of his product's evolution.
I've made extensive use of PHP 4 and 5, Python (via Django), Node.js (via Express and Socket.io), Ruby (via Ruby on Rails and Sinatra), and Erlang (via Cowboy) to develop web applications alongside the MySQL, PostgreSQL, Redis, and Riak databases. To interact with some of these web applications, I've developed RESTful HTTP APIs and worked in C#, Objective-C, and node-webkit to create networked GUI API-client software. I have experience in implementing rich AJAX-based front-end functionality (mainly using jQuery, but recently working with AngularJS), and I'm adept at transcribing graphical layout designs into standards-compliant HTML5, CSS3 and Javascript. I am comfortable with revision-control processes (my own favorite VCS being Git), and I write thorough tests for every unit of functionality I deliver.
Much of my previous code has been developed for the cloud, either running directly on Amazon EC2 in a variety of languages, or using Google App Engine (with Java and Python) or Heroku (with Ruby) to enable transparent scaling and distribution of load between application instances. I know how to balance flexibility with speed in database design, having experience with both relational, and object- or document-based (NoSQL) storage, and having specifically used Redis, Memcached, and Amazon S3 in several environments where they better served the client's needs than ordinary RDBMS storage. I also have experience in integrating applications with a variety of other third-party services and APIs, including Facebook, Twilio, and Dropbox.
I have a hobby of learning more academic languages, such as Prolog, Clojure, and Haskell, and make heavy use of concepts borrowed from them in the projects I work on, to both speed—and reduce errors in—development. I also have a keen interest in lower-level development, with experience in game development using C and Lua, and experience in optimizing assembler for the IA-32 architecture. I have a great passion for programming in general, and I hope it's one you can put to good use.
I'm currently looking for full-time employment. If you have a job offer, or any questions for me, you can:
- E-mail me at levi@leviaul.com
- Or contact me by phone: +1 (604) 442-7689

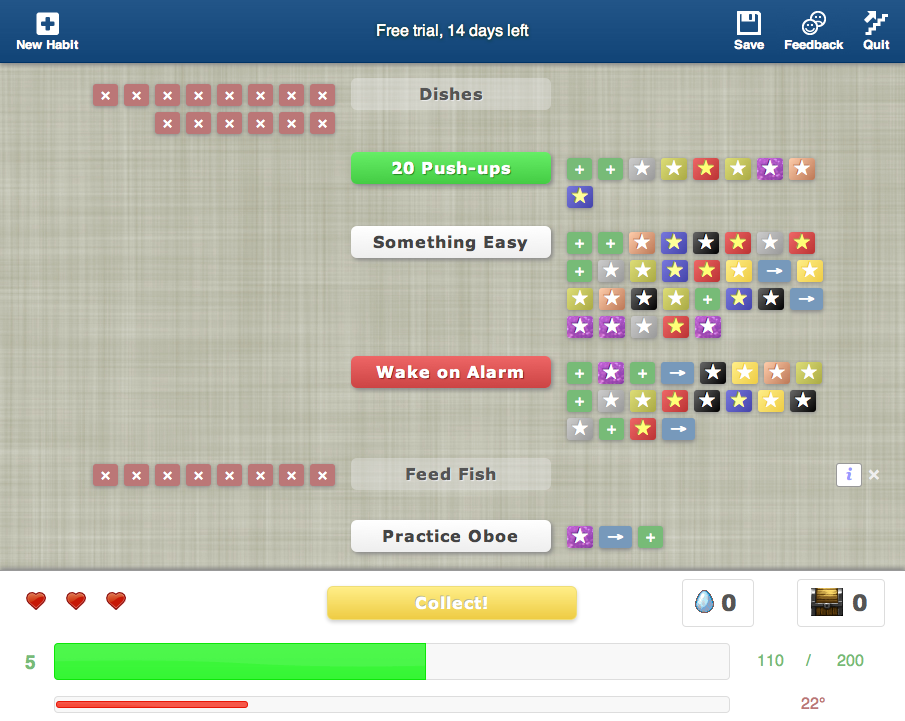
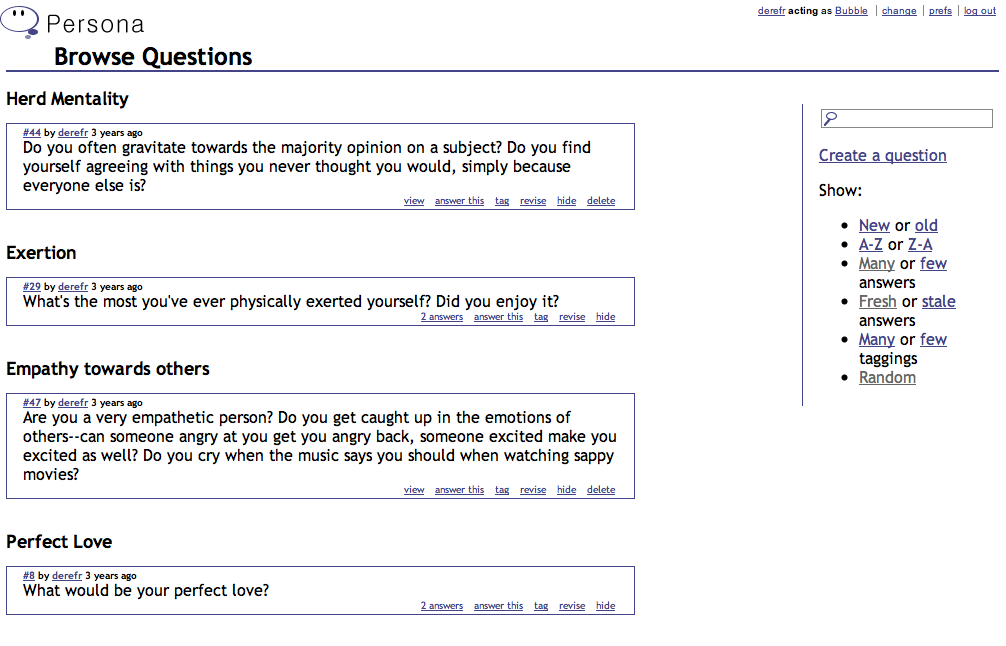
 SpiltWines is a social network to connect wine-tasters to a receptive audience, and to increase the reach of wine-reviewers. The social graph of the service represents both mutual friendships between users, and "follower" relationships between wine-reviewers and their readers. Reviews of wines can be voted on, affecting a reviewer's visibility level within the network's various public channels; users can send messages and make comments on wines and wineries; and wineries can publish PR stories on their own page.
SpiltWines is a social network to connect wine-tasters to a receptive audience, and to increase the reach of wine-reviewers. The social graph of the service represents both mutual friendships between users, and "follower" relationships between wine-reviewers and their readers. Reviews of wines can be voted on, affecting a reviewer's visibility level within the network's various public channels; users can send messages and make comments on wines and wineries; and wineries can publish PR stories on their own page.